English
English
 Français
Français
 Deutsch
Deutsch
 Español
Español
 Italiano
Italiano
 Português
Português

Written by: Nicolas Boizard, Kevin El Haddad
What are encoders in the Natural Language Processing world:
Encoders are techniques used to convert data to a numerical vector. In Natural Language Processing, they are usually used to convert words or groups of words into a numerical vector. They are essential because AI systems work only with numerical data. Not only is it necessary for an AI system to work with a numerical vector, it is crucial that the vector’s value represent the data they were converted from. For example words with the same meaning should, after conversion, have numerical values close to each other. On the opposite, words that have distant semantic values should be converted into numerical values that distant from each other.
Imagine an incoming message (email, phone call transcript, message, etc.) that should be classified automatically into a set of categories (representing for example different departments to which the message should be sent, the emotion contained in the message itself, the different types of issues this message might be associated with, etc.). In order for the classifier to categorise this message, the message should first be transformed into a numerical vector so that the classifier can apply its computation process to it as shown in the following figure.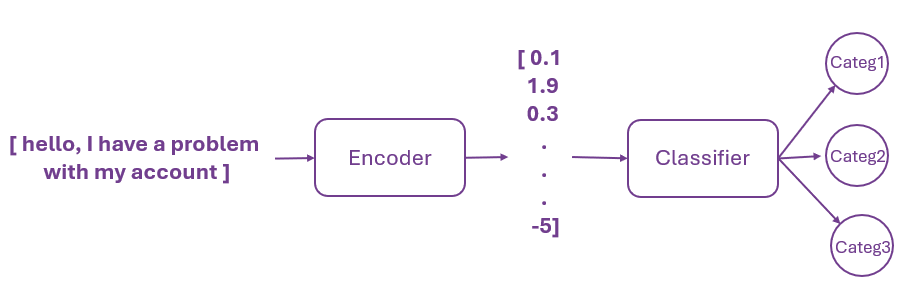
Encoders date back to a very long time ago, but they truly rose with the rise of AI in the 1990s mainly for image and speech data, all the way to 2018 when the model BERT appeared, revolutionizing the NLP world by providing a model able to encode text semantics into numerical vectors, thus improve automated language understanding.
A plethora of truly amazing work has happened since, giving birth to models fueling innovation in downstream applications relying on encoders (automatic classification, topic modeling, information retrieval, etc.).
Nevertheless, with the rise of Large Language Models (LLM) of which ChatGPT was one of the first very famous product, we thought a new training method incorporating approaches closer to industrial and business needs would give us solutions more adapted to our needs.
Eurobert A model to Tackle Business Use-cases
EuroBERT was conceived for business use cases and trained on relevant tasks in mind.
For this several dimensions were considered that were deemed of importance to business use-cases:
Languages:
Our goal is to cover as many languages as possible to answer to as many market needs as possible. We therefore naturally first started with European languages (English, French, German, Spanish, Italian, Polish, Portuguese, Dutch, Turkish). Although EuroBERT is oriented towards European languages, it was trained with other widely spoken languages like Arabic, Hindi, Turkish and Chinese along with European languages. We hope to be able to provide solutions for more languages in the future, building on the EuroBERT project.
Model’s size:
A model’s size affects parameters like its computation speed, performance and efficiency.
Our work focused on producing a suite of EuroBERT models of three different sizes with 210 million, 610 million and 2.1 billion parameters respectively. This suite allows for more flexibility across applications. Indeed application requiring a faster reactivity and less picky on performance accuracy could use the smaller models offering not only a higher reactivity speed but also being less costly and more efficient. On the other hand, bigger models are more suited for application with high accuracy requirements.
Tasks on which the models were trained:
The tasks we focused on building the EuroBERT suite tend to reflect challenges found in the industry today. We evaluate encoder models across multiple subtasks:
- Retrieval tasks: Measure how well the model finds relevant information. We test this on MIRACL (multilingual text), CodeSearchNet (code), and MathFormula (math expressions).
- Inference tasks: Check if the model can understand and reason about sentences. We use XNLI for this.
- Sequence regression: Evaluate how well the model predicts numerical scores. We use WMT for this.
Models Performance:
When compared to their peers, the suite of models provided show similar or better results in European languages as can be seen in the following table.
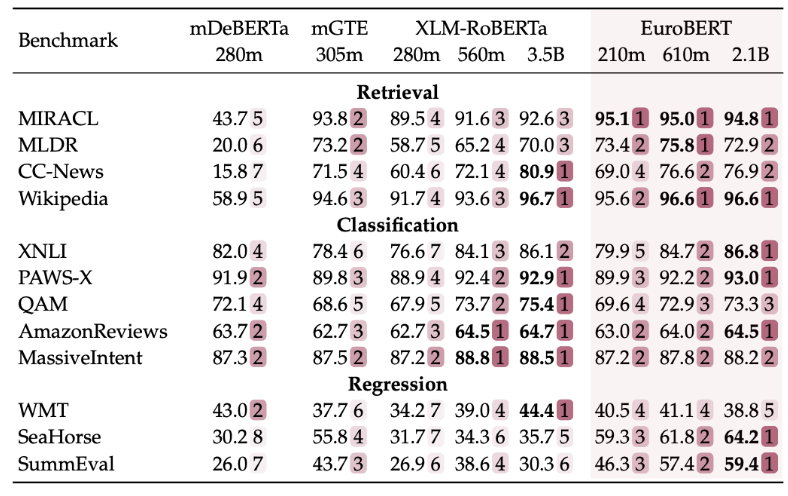
In this table, each row represents a dataset that is known to be used to benchmark models in the different tasks mentioned above.
Our Open Source Approach
The models and the data are made open source because we believe that open sourcing combined with a community driven approach speed up projects’ development, greatly contribute to increasing its robustness and help them mature into real world problem answers. So, we hope this work will benefit the community in any way and we are looking forward for their feedback and contributions.