English
English
 Français
Français
 Deutsch
Deutsch
 Español
Español
 Italiano
Italiano
 Português
Português

Authors: Gaurav Maheshwari, Soraia Lima, Kevin El Haddad
In the world of AI-powered communication, Automatic Speech Recognition (ASR) is a cornerstone technology and systems like Whisper are transforming how businesses transcribe, analyze, and respond to voice interactions at scale. From powering voice assistants to enabling accessibility, the speed and accuracy of ASR systems are paramount. At Diabolocom, this technology is central to our operations, particularly for generating live transcriptions of customer calls. These transcripts provide immediate assistance to human agents and enable vital downstream tasks like the creation of voicebots and automated quality assurance.
This process, however, hinges on a crucial factor: the human agent’s experience. How can we effectively measure a system’s qualitative performance and its perceived responsiveness from their point of view?
Answering this question requires moving beyond traditional benchmarks. The industry has long relied on the Real-Time Factor (RTF), calculated as:
RTF = Audio Duration / Processing Time
While a lower RTF indicates faster processing, the metric’s simplicity belies a more complex reality: it often fails to capture the nuances of the human experience. Imagine two ASR systems with RTFs of 0.5 and 0.4. On paper, one is 20% faster. But what if, to a human observer, both deliver transcripts with the same perceived smoothness and timing?
This perceptual equivalence fundamentally changes the decision-making calculus. If two systems feel equally responsive, it becomes far more strategic to choose the one that offers greater accuracy or better cost-effectiveness, even if its RTF is marginally higher.
In searching for tools to conduct this kind of nuanced, human-centric evaluation, we found a notable gap in the open-source landscape—a gap we decided to fill by developing our own solution.
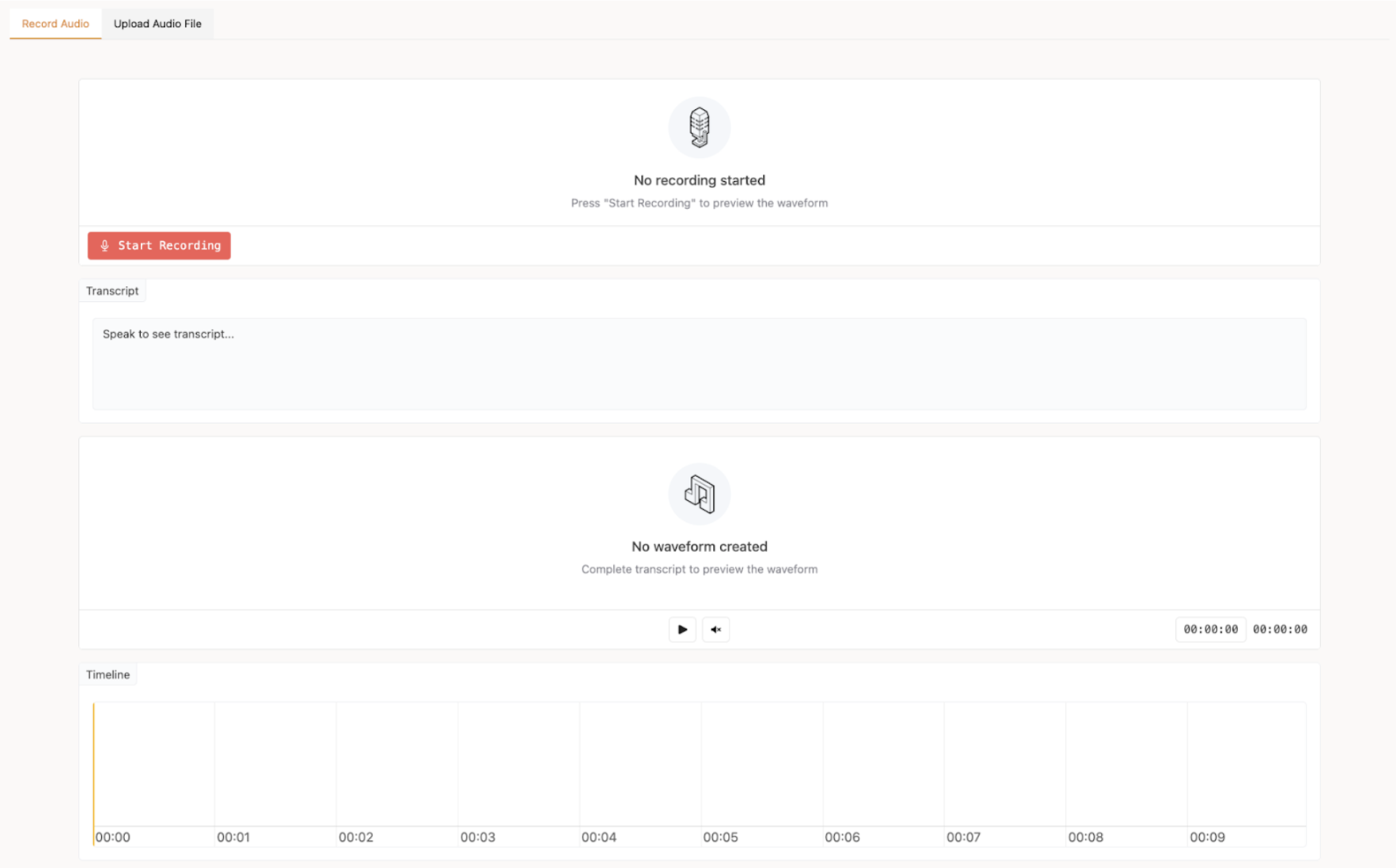
Introducing the HISI Interface: See Your Transcription in Action 🎤
To bridge this gap, we found it essential to observe the system transcribing speech in real time as we listened. So, we developed the Hear It, See It (HISI) Interface: a reactive, modular, real-time ASR testing environment. We’re proud to announce that we are making it open-source for the entire community to use and improve! This tool provides a visual and interactive way to assess ASR performance, moving beyond abstract numbers to a tangible experience.
A Reactive & Interactive UI
Our interface allows you to see transcriptions materialize as they are spoken. Key features include:
- Live Transcription: Stream audio directly from your microphone via WebRTC and watch the ASR model transcribe in real time.
- File Upload: Easily upload and process pre-recorded audio files.
- Interactive Timeline: The transcription is displayed on a visual timeline. You can click on specific word segments to play back the corresponding audio, allowing you to instantly verify accuracy and timing.
“Bring Your Own Model” Architecture
We understand that the ASR landscape is highly diverse, with custom solutions increasingly tailored for real-time applications. That’s why we designed our interface to be fully modular. It allows you to effortlessly “plug in” different ASR models—whether they operate in real time or not. Whether you’re using a well-known model like Whisper or a bespoke internal engine, the interface is built to adapt seamlessly to your setup.
This is achieved through a clean architecture based on protocols. By implementing our ASRBase abstract class, you can make your own model compatible with the inbuilt real-time processing engine based on whisper online. For those needing full control, you can even provide a completely custom real-time engine.
Engineered for Low Latency
When evaluating an ASR model’s speed, the last thing you want is for the testing tool itself to be a bottleneck. Our ASR Interface is built for performance:
- Data Transfer: We use WebRTC for real-time audio streaming, leveraging the high-performance FastRTC library from HuggingFace. This technology is designed for low-latency communication, ensuring that the delay between speaking and processing is minimal.
- Minimal Overhead: The tool’s architecture is optimized to add negligible delay. This ensures that what you’re evaluating is the performance of the ASR model itself, not the overhead of the interface.
Our Commitment to Open Source & Your Contribution 🤝
At Diabolocom, we believe that collaboration fuels innovation. By open-sourcing the ASR Interface, we hope to provide a valuable tool for developers, researchers, and companies working with speech technology. We want to empower the community to build and evaluate better, faster, and more accurate ASR systems.
This project is now yours as much as it is ours. We invite you to explore it, use it for your projects, and contribute to its future.
🚀 Check out the project on our GitHub repository!