 English
English
 Français
Français
 Deutsch
Deutsch
 Español
Español
 Italiano
Italiano
 Português
Português


Written by: Gaurav Maheshwari, Dmitry Ivanov, Theo Johannet, Kevin El Haddad
While developing our speech-related modules, we identified a critical need for more tailored resources to effectively evaluate Automatic Speech Recognition (ASR) systems in conversational settings. One of our primary objectives is to create robust AI systems capable of handling real-world, in-the-wild conversational speech. However, our testing with popular publicly available datasets revealed a significant performance gap between the results on these datasets and the system’s performance on actual conversational phone call data.
In our previous blog post, we unveiled a new dataset crafted to challenge and benchmark Automatic Speech-to-text Recognition (ASR) systems in real-world, conversational settings. With meticulous pre-processing and attention to detail, we built a dataset that’s not only clean but also mirrors the messy, unpredictable nature of real-life conversations.
In this post, we take things further by putting cutting-edge ASR systems to the test on this demanding dataset and compare their performance with established benchmarks. 🚀
⚠️ Spoiler Alert for the Impatient! ⚠️
We see a dramatic drop in performance for conversational speech. For example, CANARY shines with a stellar Word Error Rate (WER) of 19% on LibriSpeech, but its WER skyrockets to 54% 📉on the TalkBank dataset. Similar trends emerge for other models, highlighting a critical gap in ASR capabilities. Our analysis dives even deeper, revealing how speech disfluencies (umms, ahhs, pauses, and more) correlate strongly with WER.
💡 Takeaway: ASR systems still struggle with conversational speech, and current benchmarks fail to fully capture these challenges. It’s clear—we need to raise the bar to make ASR truly conversation-ready. Let’s explore in more depth!
Experimental Setup 🧪🎙️
To investigate the performance drop observed in conversational ASR tasks, we evaluate several state-of-the-art ASR models on the TalkBank dataset and benchmark their results against other standardized datasets. Here’s a breakdown of our experimental setup:
Models Evaluated 🤖
We benchmark three families of open-source ASR models, each leveraging distinct architectures and training methodologies:
- Whisper 🌐: Whisper employs a transformer-based encoder-decoder architecture trained on a vast multilingual dataset using 30-second audio segments. We use the Whisper Large V3 multilingual model, featuring 1,550M parameters, for our experiments.
- wav2vec2 📡: This model utilizes self-supervised training to predict correct latent representations among candidates, followed by fine-tuning for ASR. For our study, we use the wav2vec2-XLSR-Multilingual-56 model, designed for robust multilingual performance.
- Canary 🦜: Canary adopts a FastConformer architecture instead of Whisper’s transformer and incorporates dynamic batching, eliminating the reliance on fixed 30-second segments. We experiment with its 1B parameter multilingual model, which promises speed and efficiency improvements.
Reference Datasets 📚
To contextualize ASR performance on TalkBank, we compare results against well-established, standardized datasets widely used in speech literature:
- LibriSpeech (LS): A dataset derived from audiobooks on LibriVox, processed into short sequences with highly accurate transcripts. It provides a clean and structured dataset for benchmarking ASR models.
- Fleurs (FL): Sourced from FLoRes-101, this multilingual dataset comprises Wikipedia sentences narrated by native speakers and validated for quality.
- CommonVoice (CV): Created and managed by Mozilla, this is a massive multilingual dataset where volunteers record and validate sentences. Its crowdsourced nature makes it highly diverse and realistic.
Metric 📚
We use Word Error Rate (WER) to evaluate the performance 📊of the ASR systems. It measures the accuracy of the system’s transcriptions by quantifying the errors made when converting speech to text. Lower WER values indicate better performance, with a WER of 0 signifying a perfect transcription. Here’s how it works:
Definition
WER is calculated as: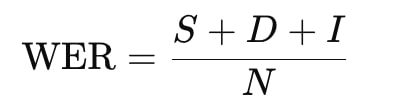
Where:
- S: The number of substitutions (words replaced incorrectly).
- D: The number of deletions (words omitted).
- I: The number of insertions (extra words added).
- N: The total number of words in the reference transcription (ground truth).
For example: If the reference transcription is “The cat sat on the mat”, and the ASR system outputs “The dog sat on mat”, the WER is calculated as follows:
- Substitution: “cat” → “dog” (1 substitution)
- Deletion: “the” before “mat” is missing (1 deletion)
- Insertion: None (0 insertions)
- Total words in reference: 6
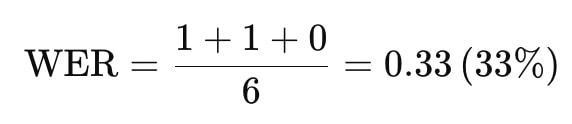
Results and Analysis 📊
With the experimental setup in place, let’s dive into the results of our benchmarking study. The primary goal of this study is to evaluate how modern ASR systems perform in conversational settings, using the multilingual TalkBank dataset, and compare their results to standardized datasets such as LibriSpeech (LS), Fleurs (FL), and CommonVoice (CV).
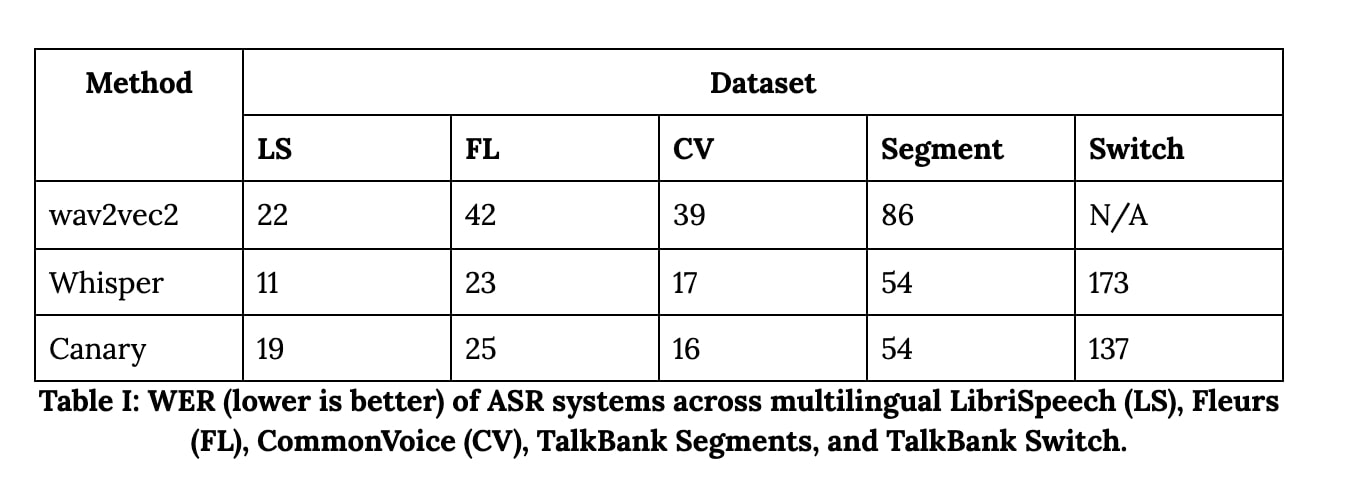
Table I: WER (lower is better) of ASR systems across multilingual LibriSpeech (LS), Fleurs (FL), CommonVoice (CV), TalkBank Segments, and TalkBank Switch.
Key Takeaways 🔑
- Overall Performance
All ASR models demonstrate significantly worse performance on the TalkBank dataset compared to LS, FL, and CV datasets. This highlights the challenges posed by real-world conversational speech, such as overlapping speakers, disfluencies, and unstructured dialogue. - TalkBank Variants: Segments vs. Speaker Switch
When analyzing the two variants of TalkBank—Segments (short, cleaner audio snippets) and Speaker Switch (conversation with interruptions and overlapping speech)—all models performed markedly better on the Segments variant. The difference in performance is substantial, with WER being over three times lower on Segments compared to Speaker Switch.
Language-Specific Analysis 🌍
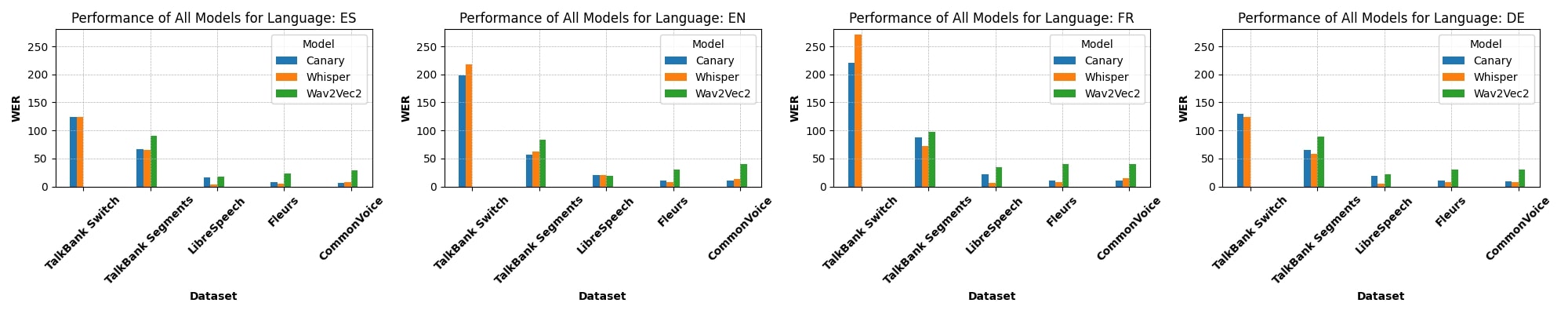
In Figure 2, we evaluate ASR systems across multiple languages:
- English consistently shows the best performance among all languages.
This trend is likely due to the predominance of English data in the training sets of these ASR models, leading to better optimization for English speech. - For non-English languages, the performance gap narrows, with similar WER values across different ASR models.
This uniformity suggests that the models are less optimized for non-English languages, reflecting the challenges of achieving equitable performance across multilingual datasets.
Impact of Audio Duration ⏳
Table II: WER (lower is better) of ASR systems on TalkBank Segments based on different time durations: Audio segments shorter than 5 seconds (T < 5), between 5 and 10 seconds (5 < T < 10), between 10 and 20 seconds (10 < T < 20), and longer than 20 seconds (T > 20).
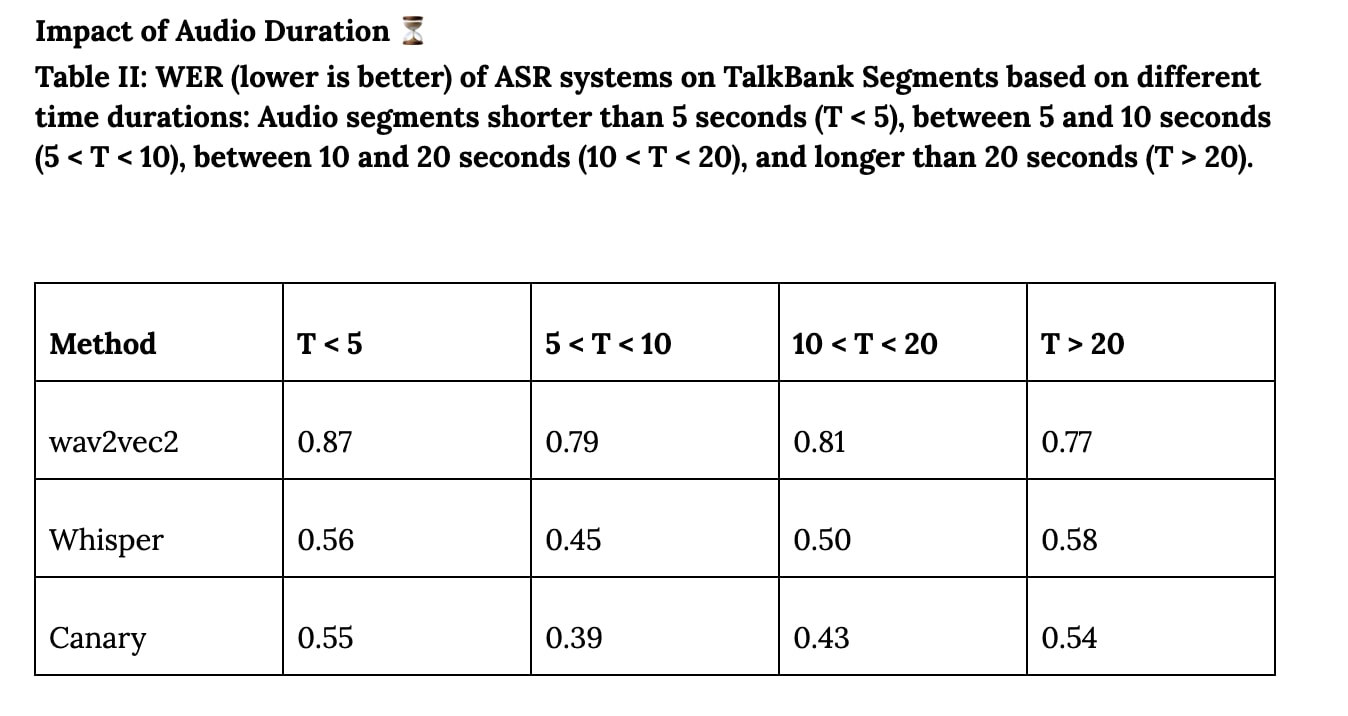
Our analysis of performance across varying audio durations reveals that time segment length has minimal impact on WER. This can be attributed to the fact that most ASR models are pre-trained on short audio segments, which aligns closely with the durations of TalkBank Segments. As a result, these models are robust to variations in segment length within conversational datasets.
What Do the Results Tell Us? 💡
These findings underline the significant challenges ASR systems face in conversational speech, particularly in multi-speaker and less-structured environments. While current models perform well on clean, structured datasets like LS, FL, and CV, their limitations in real-world settings like TalkBank highlight the need for further research and development.
The Impact of Conversational-Specific Elements on WER 🎙️📈
In this experiment, we investigate how ASR systems grapple with the unique challenges posed by natural, conversational speech. Real-world conversations are rich in non-standard elements that can influence transcription accuracy. These conversational-specific markers include:
- Non-Verbal Cues 🤔: Sounds like “mhh,” “mhm,” or “umph” that convey understanding or hesitation.
- Events 🤧: Audible actions such as coughing, groaning, or sneezing.
- Special Characters 🎵: Indicators of speech intonation, such as shifts to higher pitch or a mid-tone fall.
- Special Event Terminators ✋: Markers of trailing off, interruptions, or questions in speech.
What We Found
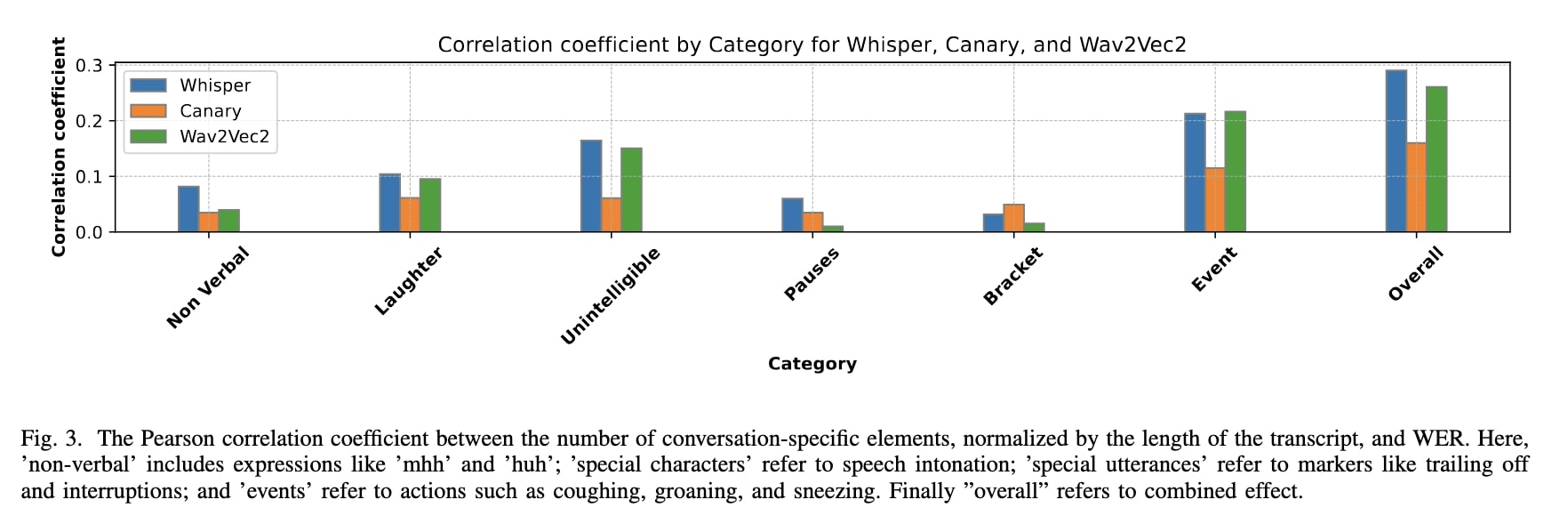
In Figure 3, we visualize the correlation between these markers (normalized by transcript length) and the corresponding Word Error Rate (WER).
- Events and Special Characters: These elements show a strong positive correlation with WER, suggesting they pose significant challenges to ASR systems. Their irregularity and ambiguity likely increase transcription errors.
- Pauses and Utterance Terminators: Interestingly, models exhibit robustness to these features, indicating that interruptions or trailing speech do not heavily degrade performance.
Key Takeaway
These findings reveal that conversational-specific markers play a pivotal role in ASR performance, with certain markers (like events and special characters) disproportionately affecting WER. This underscores the need for ASR systems to better handle the inherent messiness of natural conversations, making them more reliable for real-world applications.
Conclusion 🚀
Our study highlights the substantial challenges faced by modern ASR systems when tasked with real-world conversational speech. While these systems perform admirably on clean, structured datasets like LibriSpeech, their performance deteriorates significantly in conversational environments, as evidenced by the sharp rise in WER on the TalkBank dataset. This performance drop is further exacerbated by the presence of conversational-specific elements such as non-verbal cues, speech events, and special characters, which introduce complexities not typically encountered in standard benchmarks.
Moving forward, the ASR community must prioritize developing models that can effectively navigate these conversational intricacies. By addressing these limitations, we can push the boundaries of ASR technology, making it more robust, inclusive, and ready for real-world deployment. The journey is far from over, but understanding these challenges brings us one step closer to truly conversational AI. 🌟
