 English
English
 Français
Français
 Deutsch
Deutsch
 Español
Español
 Italiano
Italiano
 Português
Português


Written by: Gaurav Maheshwari, Dmitry Ivanov, Theo Johannet, Kevin El Haddad
🎙️ Breaking the Silence: The Real Challenge for ASR Systems
Automatic Speech-to-text Recognition (ASR) systems have made incredible strides in recent years, with state-of-the-art models like Whisper, wav2vec2, and Kaldi delivering impressive accuracy on benchmarks such as LibriSpeech and Fleurs. However, these popular benchmarks often represent idealized conditions, such as audiobooks 📚or carefully recorded sentences spoken by native speakers in quiet environments.
In contrast, everyday interactions occurring in application areas like call center interactions automation, and voicebot assistants for smart homes, hospitals and self-driving cars, are riddled with complexities: speakers interrupt each other, accents and dialects vary, and disfluencies like “uh” and “um” abound. ASR systems tested only on controlled datasets fail to reflect the challenges of such natural settings, where performance often degrades significantly.
To tackle this, we’re thrilled to introduce a new multilingual conversational dataset derived from TalkBank 🎉This dataset captures the essence of real-world phone conversations—unstructured, spontaneous, and rich in variability. Preparing such a dataset for ASR benchmarking, however, requires careful preprocessing to ensure its reliability and relevance.
In this blog, we take you behind the scenes of dataset preparation, exploring the processes and considerations involved in transforming raw conversational data into a robust resource for advancing ASR research. Join us as we pave the way for ASR systems to excel not only in benchmarks but also in the complexity of everyday conversations.
The TalkBank Dataset: A Conversational Treasure Trove 🗣️
TalkBank is a goldmine of spoken language data, offering researchers a comprehensive collection of 14 subcomponents tailored to diverse domains. They consist primarily of audio recordings of people interacting accompanied with manual transcriptions. For our work, we focused on one particularly rich resource: CABank, a dataset designed for analyzing conversations between adults. Within CABank, the CallFriend and CallHome datasets stand out, offering recordings of phone conversations in multiple languages. These datasets capture the nuances of real-world speech, making them ideal for conversational ASR evaluation. However, using these datasets for ASR applications come with challenges:
- 🎧Misaligned audio and transcripts.
- 🔄Lack of speaker-channel information.
- 📝Complex transcript formats incompatible with ASR evaluation.
Ensuring Dataset Quality: Preprocessing for Clean and Consistent Data 🔧✨
Creating a high-quality dataset isn’t just about collecting data—it’s about transforming it into a resource that researchers can trust. To ensure that our dataset is clean, consistent, and ready for advanced ASR benchmarking, we implemented a series of meticulous preprocessing steps. Here’s how we refined the raw data into a polished conversational dataset:
1️⃣ Manual Filtering 📝
Our first step was to manually review the audio files and their transcripts to identify and remove problematic data. We excluded:
- Files where the transcripts and audio didn’t match at all.
- Instances with only one speaker, as these lack conversational dynamics.
2️⃣ Aligning Speakers with Channels 🔊👥
The TalkBank corpus doesn’t provide speaker-channel mapping, which is crucial for ASR tasks. To solve this, we used a Voice Activity Detection (VAD) method, allowing us to accurately associate speakers with their respective audio channels.
3️⃣ Removing Annotations Without Timestamps ⏱️
Annotations without timestamps are unusable for ASR evaluation because the timestamps indicate which text segments correspond to which audio segment. After identifying speaker channels, we filtered out any annotations that lacked timestamp information.
4️⃣ Aligning Timestamps with Speech Segments 🎙️📐
During manual checks, we noticed some annotation timestamps were misaligned with the actual speech, often cutting off segments prematurely. Using a VAD model, we refined these timestamps by:
- Extending end timestamps to include complete speech segments when they fell short.
- Ensuring annotations accurately capture the spoken content.
5️⃣ Discarding Inconsistent Audio Segments 🗑️
Even after extensive filtering, some audio segments still had inaccurate transcripts—often cutting off prematurely or mismatched entirely. With over 100,000 audio segments, manual inspection wasn’t feasible. Instead, we developed an ASR-based automated filtering process:
- Two distinct ASR models transcribed each audio segment.
- Files where both models produced similar outputs with a high Word Error Rate (WER) were discarded.
This method leverages the principle that different ASR models are unlikely to produce identical errors unless the issue lies with the transcript itself.
6️⃣ Removing Special Symbols ✂️🔣
TalkBank transcripts are formatted in CHAT, which includes special symbols for conversational events (e.g., laughter, pauses, and non-verbal expressions). These symbols complicate direct comparisons between ASR outputs and transcripts. We addressed this by replacing special symbols with empty strings, simplifying the data for ASR evaluation.
Exploring Alternative Segmentation: TalkBank Switch vs. TalkBank Segments 🔄🎙️
When working with conversational datasets, the way the speech is segmented can significantly influence the model’s performance. While the default segmentation provided in TalkBank, which we refer to as TalkBank Segments, divides the data based on pre-existing annotations. Apart from this variant available as part of the released dataset, we also explored an alternative approach: speaker-based segmentation.
What is Speaker-Based Segmentation? 🗣️
Instead of relying on the original annotations, we merged all consecutive segments attributed to the same speaker into a single, larger audio segment. This method, which we call TalkBank Switch, resulted in:
- Fewer audio segments: By grouping consecutive turns from the same speaker.
- Longer audio segments: Allowing for more context within a single segment.
Why Explore This Approach? 🤔
Speaker-based segmentation offers the potential to provide models with more coherent and context-rich audio, possibly improving their ability to capture linguistic patterns and speaker dynamics. However, it also introduces challenges, such as handling longer audio inputs and ensuring that transitions between speakers remain well-defined.
Final Dataset: Multilingual and Ready for Real World ASR Benchmarking 🌍🔊
After undergoing a comprehensive preprocessing pipeline, the final dataset comprises 151,705 audio segments in the TalkBank Segment variant and 2,073 segments in the Speaker variant. Both variants encompass eight languages and are meticulously curated to ensure consistency, reliability, and suitability for advancing conversational ASR research.
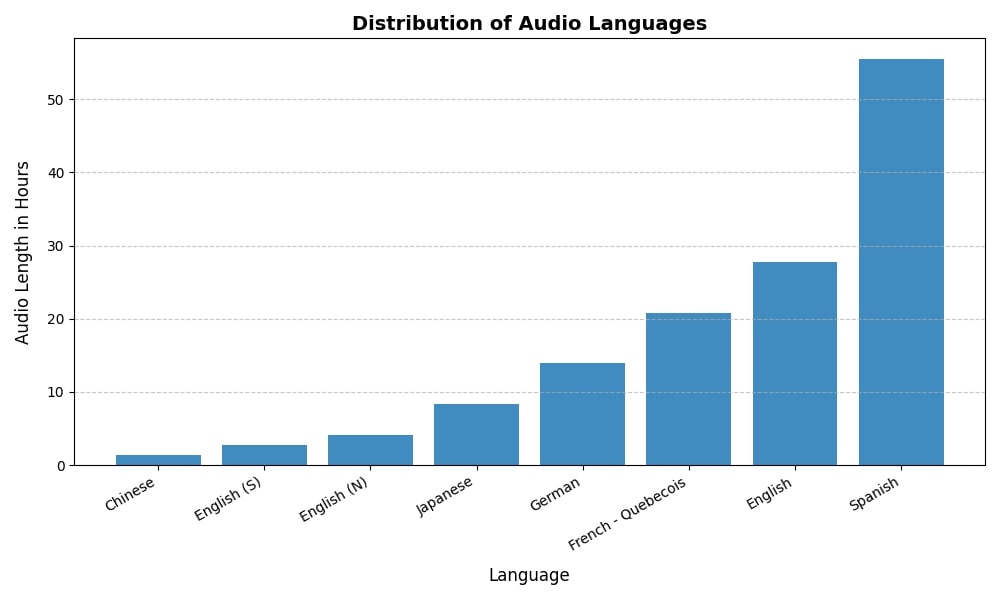
Language Distribution 📊
The dataset’s distribution by total audio duration across languages is shown in the figure above. This breakdown highlights the multilingual nature of the dataset, offering diverse linguistic contexts for robust ASR evaluation.
Test-Train Splits 🧩
To ensure consistency with existing benchmarks, we followed the same test-train split proportions per language as the widely used CommonVoice dataset. This approach enables fair comparisons and compatibility with existing research in the ASR domain.
Accessing the Dataset 🔗
The dataset, complete with test-train splits and detailed preprocessing documentation, is available in our source code repository. By sharing this resource, we aim to empower researchers to advance ASR systems that can tackle the complexities of real-world, conversational speech. Stay tuned for upcoming results and insights as we benchmark this dataset! 🚀
A more representative dataset!
This dataset was used to benchmark the performance of several ASR models alongside mainstream state-of-the-art datasets such as Librispeech, CommonVoice, and FLEURS. We find a noticeable performance drop, underscoring the need for a more representative dataset tailored to user interaction tasks, particularly those conducted over the phone. For a deeper dive into this experiment, visit our detailed write-up.
